
Gaussian Splattingでいい品質にするにはどうすればいいか、といろいろ試行錯誤していました。
ある程度まとめることができる段階になりましたので、検証結果を書き連ねていくことにしました。
ただし、これは2023/10/01段階での検証範囲の個人的な所感ですので、あくまでも参考程度の情報と見てくださいませ。
Gaussian Splattingのオリジナルは https://github.com/graphdeco-inria/gaussian-splatting を使用します。
「Gaussian Splattingを試す (Windows)」もご参照くださいませ。
今回は「オリジナルの画像の品質を高めて、最終的なレンダリング品質を確保する」ための調整がテーマになります。
検証環境
- OS : Windows 10
- Mem : 64 GB
- GPU : NVIDIA RTX A5000 (24GB VRAM)
Gaussian Splattingの作業工程
Gaussian Splattingに渡すデータとして「静止画」を複数枚用意する必要があります。
これらをconvert.pyに渡すことでCOLMAPを使ってカメラの位置や姿勢、レンズのゆがみが推定されることになります。
これ自身はGaussian Splattingのトレーニングではなく、前処理になります。
この段階で精度が悪ければトレーニングもうまくいかないようでした。
以下の流れで処理を行うことになります。
- 動画を撮影
- 動画から静止画を切り出し
- convert.pyでのCOLMAPを使ったカメラ推定。使用できない画像の除去。Pinhole画像化。
- train.pyを使ったトレーニング
Panorama180 To Pinhole : 動画からPinhole画像を生成
撮影はGoPro 12 + Maxレンズモジュラー2.0を使用しました。
Gaussian Splattingの前処理を行うconvert.pyは、GoProの若干の魚眼も自動的にPinholeに変換してくれます。
ただし、GoProは広角ですのでそのままGaussian Splattingに渡すと端の方が不自然になってしまいます。
Maxレンズモジュラー2.0を使った画像をconvert.pyに渡した場合は、もっと端が間延びしてしまいます。
そこで、convert.pyに渡すよりも前の段階で任意の視野角度でPinholeの画像に変換するようにしました。
UnityでGoProやパノラマ(Equirectangular、FishEye)の動画を入力し、静止画として出力するアセットを作りました。
Panorama180 To Pinhole
https://github.com/ft-lab/Unity_Panorama180ToPinhole
使い方はこのURLのトップ(readme)をご参照くださいませ。
このアセットを使うことで、動画の1フレームから正面と上下左右の合計5枚/フレームのPinhole画像を出力します。
これを使う目的は、カメラで撮影した正面だけでなく、見落としやすい上下もトレーニングに含めたいというのがありました。
以下は、GoPro 12 + Maxレンズモジュラー2.0を使い、魚眼として撮影したものです。

GoPro 12 + Maxレンズモジュラー2.0については、「[GoPro] GoPro HERO 12 + Maxレンズモジュラー2.0を試す(魚眼)」もご参照くださいませ。
撮影された動画自身は魚眼ですが、このアセットを使うことで少し上下左右を向いたときの静止画も得ることができます。

地面も結構な品質で確保できているのを確認できます。
Unity Editor上では以下のようになります。
指定のフレーム間隔でPinholeの静止画を出力していきます。
正面向き、左向き、右向き、上向き、下向きをグループとして連番で静止画が生成されます。
この「静止画として連続している」というのが非常に大事な要素になります。
元画像の品質
元画像の品質が悪いとconvert.py(COLMAP)の計算自身が正しくなくなるのに加えて、計算時間がかかってしまいます。
うまくいった場合と比べても、10倍以上時間がかかることもありました。
静止画を作るにあたってのチェック項目を列挙します。
これがうまくいっていないと、その後のconvert.py、train.pyも時間がかかったりいまいちな結果になりました。
1枚1枚の静止画でブラーやボケがかかっていないか
これはGoProの撮影ではないのですが(Insta360 EVOを使っていた過去の撮影)、失敗につながります。
ボケていて不鮮明な所が多いです。

これについては、Insta360 EVOの動画から1フレーム切り出した際にこのようになりやすかったため、カメラを変えるしかありませんでした。
ということでGoProに切り替えたきっかけでもあります。
不鮮明な画像であってもGaussian Splattingはなんとか計算してしまえるのですが、最終的な表示はやはりこの静止画のようにもやっとしていました。
これについては、あまり計算時間に影響はありませんでした。
Gaussian Splattingの最終的なレンダリング結果は撮影/生成した静止画以上の品質にはならないため、
元の静止画の段階で品質は確保しておきたいです。
連続性の確保
これが非常に大事です。
convert.pyに渡す画像は連番で指定します。
このときに、連番の画像において「カメラがわずかずつ移動している」必要があります。
連続性が確保されているか、という点になります。
連続していない画像のグループがある場合は、
グループ1 : image_000000.jpg, image_000001.jpg, image_000002.jpg,,,
グループ2 : image_100000.jpg, image_100001.jpg, image_100002.jpg,,,
グループ3 : image_200000.jpg, image_200001.jpg, image_200002.jpg,,,
のように連番を指定することが有効でした。
グループごとに静止画としては連続性が確保されているものとします。
もし、画像に連続性がない場合は計算時間がすごくかかり(convert.py, train.py共に)、最終的な結果もいまいちでした。
動画から静止画を切り出す場合は、2fps以上のサンプリングは必要かもしれません。
もちろん、GoPro撮影時のカメラの動かす速度も影響します。
基本ゆっくり移動。そうしないと、ブラーもかかってしまいますので。
画像枚数は計算時間を増加させる要因にはなりますが、
それよりも連続性の確保を優先したほうが計算時間の短縮にも最終的な品質にもつながるようでした。
同一の動画から0.5fpsでキャプチャした場合、2fpsでキャプチャした場合において、計算速度と品質を比較してみました。
静止画像のサイズ : 1000 x 800
動画内でのキャプチャ時間 : 80秒
| 検証パターン | キャプチャfps | 画像枚数 | convert.pyの計算 | train.pyの計算 |
|---|---|---|---|---|
| 連続性を粗くした | 0.5 | 195 | 約45分 | 約30分 |
| 連続性を細かくした | 2.0 | 795 | 約160分 | 約30分 |
1フレームで5枚ずつ出力しているため、(80秒 x 2fps) x 5 = 800
0.5fps(195枚)の場合の最終結果。
影になっている壁部分がばらけています。
2fps(795枚)の場合の最終結果。
かなりよくなりました。
空間が静止しているか
草木が風で揺れている、というようなパターンはカメラ推定にも影響しますし、最終的な結果の劣化にもつながります。
これはフォトグラメトリでも同様ですね。
自分自身の影
以下のようなのはノイズにつながります。

最終的な静止画をチェックしこのような画像を削除するのもいいのですが、
そうすると連続性が確保出来なかったり死角になる領域が出る可能性があるため、撮影段階で影が落ちないように注意するのがよさそうです。
露出の変化が激しい場合
野外から室内に入るような撮影の場合、自動露出により露出が変化することになります。

この場合、Gaussian Splattingでは以下のようにすごくモヤがかかるような感じになりました。
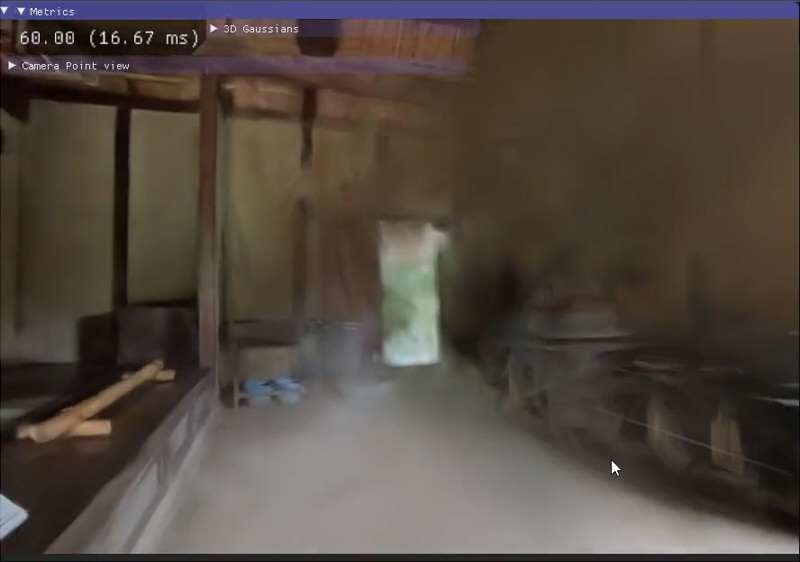
これは、部屋の中自体が暗いためその影響かもしれないですが、、。
また、露出の変化が激しい場合はconvert.pyやtrans.pyの計算時間も増加してしまうように感じました。
露出変化が激しいシチュエーションは避けるのがよさそうです。
かといって、自動露出を無効にし全体が暗い静止画があるとカメラの推定は失敗すると思います(試してはいないです)。
あと、室外でも木々から入る木漏れ日、も露出変化が激しかったです。
レンズフレアも推定を乱す要素になるため、注意したほうがよさそうです。
静止画の解像度
Gaussian Splattingでは、train.pyで1.6K以上の解像度の場合はデフォルトでは自動的に縮小されます(オリジナルサイズを使用できるオプションもある)。
解像度はconvert.pyおよびtrain.pyの計算時間にかなり影響するようでした。
GPUのVRAMの消費は解像度に依存するようです。
ということで解像度として1.5Kくらいのギリギリを攻めたのですが、この場合はtrain.pyにおいてGPUのVRAMを23.5GBくらい消費し計算時間もすごくかかっていました。
むしろ、4K解像度の静止画のほうがVRAM消費も計算時間も抑えることができていました(1.6Kよりももっと縮小して計算している?)。
1.0K解像度(1000 x 800など)くらいだと18-20GBくらい消費でなんとかなる感じでした。
1.2K解像度(1200 x 900など)くらいだと23-23.5GBくらい消費し、計算時間も増えるようでした。
1.6K解像度以下の場合において、
品質は二の次にして成功しているかどうか確認したいときは、
train.pyで"-r 2"のオプションを指定すると1/2解像度で計算され、かつ、短時間で完了します。
これでまず出来を確認してみるのがいいかもしれません。
画像枚数、解像度、連続性の比較
画像枚数、解像度、連続性をそれぞれ変えて検証した結果は以下のような手ごたえとなりました。
画像枚数を増やした場合
| 処理 | GPUのVRAM消費 | 計算時間 |
|---|---|---|
| convert.py(COLMAP) | 影響はほとんどなし | 増加する |
| train.py | 影響はほとんどなし | 影響はほとんどなし |
解像度を大きくした場合
| 処理 | GPUのVRAM消費 | 計算時間 |
|---|---|---|
| convert.py(COLMAP) | 影響はほとんどなし | 増加する |
| train.py | すごく増加する | すごく増加する |
連続性の確保の有無
静止画の連番として、連続性を確保していない場合の比較です。
| 処理 | GPUのVRAM消費 | 計算時間 |
|---|---|---|
| convert.py(COLMAP) | 影響はほとんどなし | すごく増加する |
| train.py | 増加する | 増加する |
なお、COLMAPでは
- 連続性を確保しない場合(1枚1枚を静止画として撮影した場合など)
- 連続性を確保した場合(動画からの切り出しなど)
どちらのタイプか指定するオプションがあります。
Gaussian Splattingのconvert.pyは、後者を採用している気がします。
1.0K解像度くらいの場合、convert.py(COLMAP)で綺麗にコンバートできてさえすれば
train.pyのトレーニング速度は画像枚数が増えても30分~1時間くらいで安定するようでした。
(環境にもよりますが)train.pyで時間がかかりすぎる場合、かつ、解像度の問題ではないと判断できる場合は失敗していることが多いかもしれません。
この場合は、撮影した動画(切り出した画像)自身が適切でない可能性がありそうです。
経験的にではありますが、convert.pyで1つの処理に計算時間がかかっているのが見えた場合、
失敗している可能性が高いかもしれません。
流れるようにログが出ていれば、成功している確率が高い気がしました。
ひとまずですが、今回はここまでです。
train.pyにはいくつかオプション指定があり、それにより品質調整はできるようです。
オプション指定はまだ未チェックですが、追って確認予定です。